A propos d'OFL
Contenu de la page
-
Description du modèle
- Le niveau application : OFLinstances et OFL-données
- Le niveau langage : OFL-composants
- Le niveau OFL : OFL-concepts et OFL-atomes
-
Motivations
Nous pouvons ici distinguer d'une part le modèle et d'autre part les outils logiciels que l'on peut construire pour en tirer parti. Concernant le modèle lui-même nous croyons qu'en spécifiant des relations entre classes dont la sémantique est plus précise qu'un héritage ou qu'une agrégation nous contribuons à l'amélioration de la lisibilité du code. De même, cela permet d'envisager la génération d'une documentation automatique pertinente et la réalisation de contrôles plus appropriés. Cette documentation et ces contrôles devraient en outre permettre de réduire le fossé qui existe entre l'expressivité des méthodes de conception et celle des langages de programmation.
Nous sommes cependant persuadés que, comme une utilisation excessive de l'héritage et de l'agrégation, un excès de spécialisation de ces mécanismes peut également nuire à la lisibilité. Un compromis est à trouver dans ce domaine. Une solution pourrait être de ne préciser l'usage de l'héritage ou de l'agrégation qu'à certains endroits du programme où l'effet sera particulièrement bénéfique : par exemple l'utilisation de la généralisation (en lieu et place de la spécialisation) pour ajouter une classe au milieu d'une hiérarchie sans modifier le code des classes déjà existantes. Toujours dans l'idée d'une utilisation réaliste d'OFL, nous avons aussi pour objectif de mettre à la disposition du programmeur des bibliothèques de composants-relations et composants-descriptions la description est une généralisation de la notion de classe dans lesquelles il pourra sélectionner ceux qu'il souhaite utiliser. Cette démarche s'apparente à celle visant à fournir des composants logiciels réutilisables voire des composants métiers.
Description du modèle
L'approche OFL peut, en première lecture, se résumer à la recherche d'un ensemble de paramètres dont la valeur détermine la sémantique opérationnelle d'un langage à classes. Dans l'article de LM0'2001 nous avons présenté de manière détaillée la signification de chaque paramètre et nous en avons proposé une classification qui tient compte de leurs objectifs, puis nous avons proposé une micro-application qui montre le bénéfice que peut en tirer le programmeur. Le modèle OFL est formé de deux parties principales : un système de paramètres valuables qui permet la création d'éléments de langage et un système d'actions qui sont des algorithmes représentant un morceau d'un compilateur, interprète ou exécutif dont l'exécution dépend des valeurs des paramètres.
Les explications proposées ci-dessous visent à donner un aperçu du modèle OFL. Bien que ce dernier va continuer à évoluer au fur et à mesure de l'avancée de nos travaux, il est recommandé de se rapprocher de la thèse de Pierre Crescenzo qui décrit le modèle avec plus de précision. Les transparents de sa présentation sont aussi disponibles.
La notation choisie dans les figures s’apparente à celle d’UML; elle est présentée dans la figure1 qui présente l'architecture du modèle et illustre l’utilisation du modèle OFL pour décrire une application ; elle représente à la fois une hiérarchie méta représentée par des liens d’instanciation mais aussi une hiérarchie de descriptions liées par spécialisations. Dans l’arbre d’instanciation, chaque niveau n’est relié directement qu’au niveau supérieur, par contre ce n’est pas le cas pour l’arbre de spécialisation dont l’objectif est structurel : modéliser la réification des informations qu’elles soit méta ou pas.
Nous montrons dans cette figure les trois niveaux de modélisation nécessaires :
- 1) le niveau application regroupe les descriptions et les objets du programme (OFLinstances et OFL-données), il est donc créé par le programmeur,
- 2) le niveau langage décrit les composants du langage de programmation (OFL-composants), il est sous la responsabilité du métaprogrammeur et
- 3) le niveau OFL représente la réification de ces composants (OFL-concepts et OFL-atomes), c’est-à-dire notre modélisation de la sémantique opérationnelle des descriptions et relations.
L’introduction d’un vocabulaire nouveau a pour objectif de minimiser les quiproquos concernant les termes employés. Le lecteur pourra trouver par exemple qu’une description s’apparente à une classe et qu’un composant-description se rapproche de la notion de métaclasse.
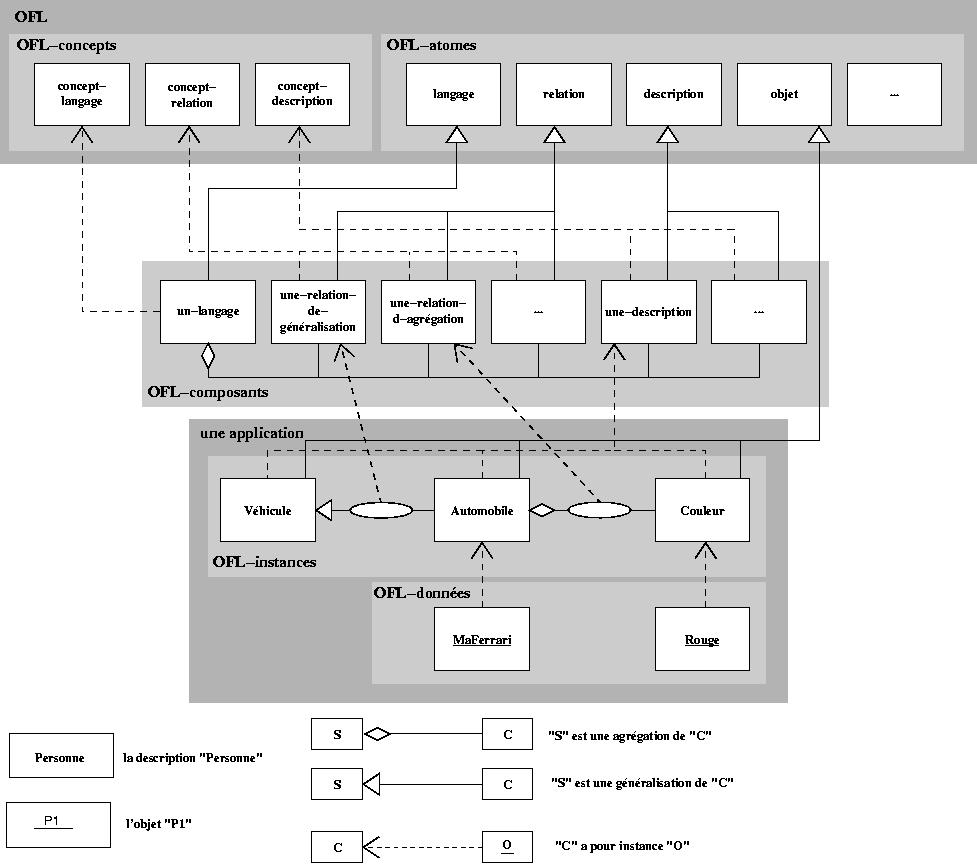
Figure 1: Architecture et utilisation
Le niveau Application
Pour décrire une application, le programmeur utilise les services offerts par le niveau langage. Il crée, au niveau application, des OFL-instances, qui sont les descriptions et les relations de son application, par instanciation des OFL-composants. À l'exécution, les objets de l'application, nommés OFL-données, sont des instances des OFL-instances représentant les descriptions.
Les OFL-instances. Chaque description ou relation décrite par le programmeur est modélisée par une OFL-instance. La figure 1 propose un exemple d'application qui comprend cinq OFL-instances :
- i) trois descriptions : Véhicule, Automobile et Couleur,
- ii) une relation de généralisation : Automobile hérite de Véhicule et
- iii) une relation d'agrégation : Automobile a un attribut de type Couleur.
Les OFL-données. Dans l'application, chaque instance de description est réifiée à l'exécution par une OFL-donnée. La figure 1 en présente deux :
- i) MaFerrari, instance de la description Automobile et
- ii) Rouge, instance de la description Couleur.
Remarquons que les OFL-instances qui représentent des descriptions spécialisent l'OFL-atome objet. En effet, objet est la réification des données de l'application (OFL-données) et constitue donc la racine de l'arbre de spécialisation des OFL-instances représentant des descriptions. objet contient par exemple la collection des attributs d'une instance de description.
Le niveau langage
Le niveau langage décrit les différentes sortes de relation et de description qu'il est possible d'utiliser dans le langage modélisé. Les relations sont des instances de concept-relation, les descriptions des instances de concept-description. Le langage lui-même est une instance de concept-langage. Il a pour principale fonction de regrouper les relations et descriptions qu'il met à la disposition du programmeur.
Les OFL-composants. La figure 1 recense :
- i) des composants-descriptions dont une-description,
- ii) des composants-relations dont une-relation-de-généralisation et aussi une-relation-d-agrégation et
- iii) un composant-langage un-langage.
Il est possible de se représenter un composant-description sous la forme d'une métaclasse, un composant-relation comme une métarelation et, de la même manière un composant-langage comme un métalangage. Les entités méta, en plus de l'aspect comportemental qui leur est associé, contiennent un ensemble d'informations fixe. Ces informations sont importées des OFL-atomes au travers d'une spécialisation.
Le niveau OFL
Le niveau OFL constitue un métamodèle pour le langage de programmation (niveau langage) et un métamétamodèle pour les programmes (niveau application). Nous avons choisi de paramétrer trois notions essentielles : les relations, les descriptions et les langages. Cependant, il est nécessaire de réifier bien d'autres composants, tels les objets, les méthodes, les assertions, etc. pour modéliser complètement un langage. Le niveau OFL contient donc deux sortes d'entités :
- 1) les OFL-concepts qui décrivent la partie paramétrable (la sémantique opérationnelle) des relations, descriptions et langages et
- 2) les OFL-atomes qui décrivent la partie non-paramétrable de ces trois concepts ainsi que tous les autres éléments.
Ajoutons enfin que des assertions sont décrites dans chaque OFL-concept et OFL-atome pour garantir la cohérence du modèle.
Les OFL-concepts. La figure 2 montre l'intégralité de la classification des OFLconcepts. La tâche du métaprogrammeur consiste à créer un OFL-composant, instance d'OFL-concept, en donnant une valeur à chacun de ses paramètres. Il définit par ce biais le comportement de chaque future instance de l'OFL-composant. Si les actions prévues n'offrent pas au métaprogrammeur la sémantique opérationnelle qu'il souhaite associer à un OFL-composant, il doit alors modifier le code de ces actions. Cette possibilité laisse le modèle OFL ouvert mais ne doit être utilisée que dans des contextes très spécifiques. En effet, le travail du métaprogrammeur est dans ce cas beaucoup plus lourd que la simple valuation de paramètres.
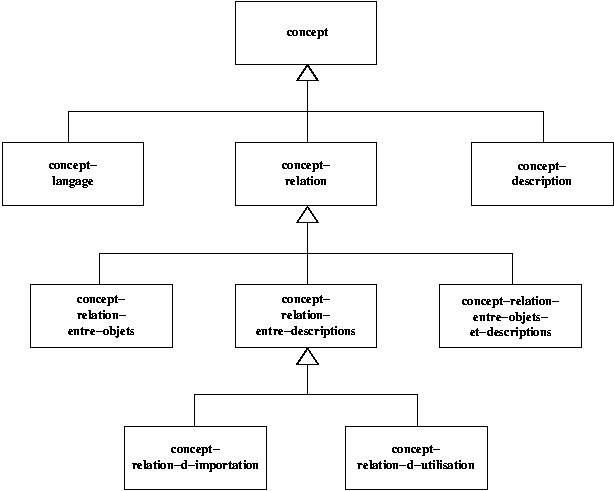
Les concepts-relations. Nous appelons concept-relation l'entité représentant une sorte de relation. Un concept-relation est donc une métamétarelation. Parmi les sortes de relation présentes dans de nombreux langages à classes et méthodes de conception à objets, nous pouvons citer par exemple l'héritage, l'agrégation, la composition, la généralisation, . . . Cependant une méthode ou un langage donné possède rarement toutes ces relations et en utilise certaines pour en simuler d'autres. Par exemple la généralisation en UML décrit aussi bien une généralisation, qu'un héritage, qu'un sous-typage strict, . . . Une trentaine de paramètres définissent la sémantique de chaque concept-relation du modèle OFL. Dans la figure ci-dessus on propose notre classification des concepts-relations. Au sein des relation interdescriptions, nous distinguons les relations d'importation (généralisation du mécanisme d'héritage) de celles d'utilisation (généralisation du mécanisme d'agrégation). La figure 2 montre un exemple d'instance de concept-relation d'importation (une-relation-de-généralisation) et un exemple d'instance de concept-relation d'utilisation (une-relation-d-agrégation).OFL prend également en compte les relations entre objets et descriptions qui permettent notamment de modéliser le lien d'instanciation qui existe entre un objet et sa description. Nous pouvons aussi modéliser les relations entre objets. Cependant, notre principale préoccupation reste les relations interdescriptions.
Les concepts-descriptions. Un concept-description permet de définir la notion de classe et de tout ce qui ressemble à une classe, comme les interfaces en Java. Un
concept-description est donc une sorte de métamétaclasse. Nous pouvons remarquer, par exemple, que les classes d'Eiffel, de C++ ou de Java, même si elles se ressemblent, présentent des différences notables. La figure 2 donne, à titre d'exemple, une seule instance de concept-description appelée une-description. Une vingtaine de paramètres sont nécessaires pour décrire le comportement d'une description dans le modèle OFL. Chaque description peut initier ou être la cible d'une ou plusieurs sortes de relation selon la sémantique qu'on veut lui donner ; les sortes de relations qui sont acceptées par (autrement dit, compatibles avec) un composant-description font partie des informations qui lui sont associées.
Les concepts-langages. Le concept-langage est une notion importante et simple. Il modélise, comme son nom l'indique à l'évidence, un langage. Chaque langage est constitué en particulier d'un ensemble de composants-descriptions et d'un ensemble de composants-relations, chacun étant compatible avec au moins un des composantsdescriptions sélectionnés. Dans la figure 2 nous avons une seule instance de concept-langage (un-langage) qui représente le langage modélisé. Les concepts-langages sont très peu paramétrés et leur principale fonction est de fédérer des composants-relations et des composants-descriptions compatibles entre eux.
Les OFL-Atomes. Les OFL-atomes représentent la réification des entités non paramétrées du modèle. Les relations, descriptions et langages possèdent également leur OFL-atome qui décrit la partie de leur structure et de leur comportement qui n'est pas paramétrée (il est donc naturel que les trois niveaux de notre architecture fassent référence directement aux OFL-atomes). Sur la figure 1 nous pouvons noter que l'OFL-composant une-relation-d-agrégation est une spécialisation de l'OFL-atome relation qui spécifie par exemple la liste des descriptions-sources et la liste des descriptions-cibles. Dans une application, toutes les primitives d'une description sont instances d'un descendant de primitive, toutes les expressions sont instances expression ou d'un de ses descendants et toutes les instances de descriptions sont aussi instances d'un descendant d'objet. OFL offre donc une réification complète des entités présentes à l'exécution d'une application.
Exemple d'utilisation des OFL-Composants
Nous venons de décrire les différents éléments qui constituent le modèle OFL. Nous proposons maintenant d'utiliser OFL pour modéliser les descriptions et les relations du langage Java. Nous recensons ici les différentes sémantiques de descriptions et de relations entre descriptions du langage Java. Chacune de ces sémantiques est représentée par un OFL-composant. Le lecteur peut se référer à la figure 3 pour avoir la liste complète des OFL-composants de Java.
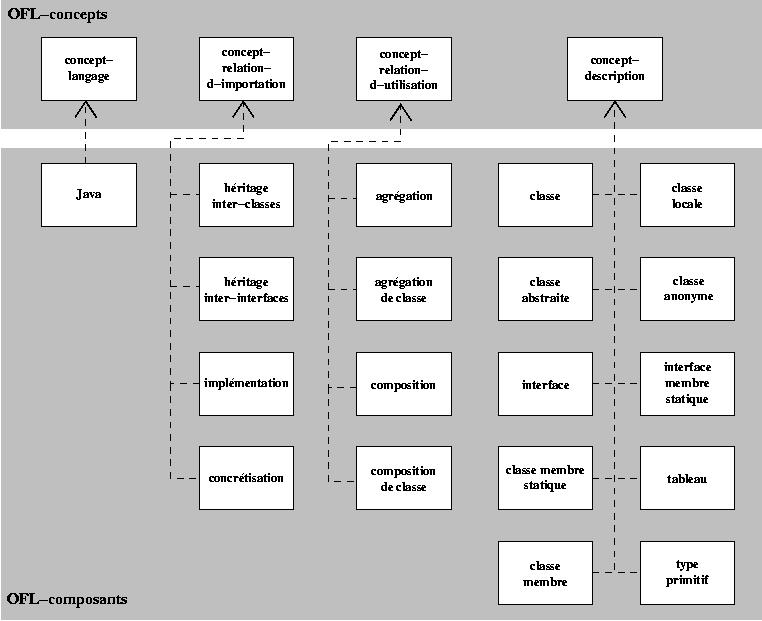
Figure 3: un exemple - les OFL-composants pour Java
Nous avons ainsi dénombré pour Java :
- i) un seul composant-langage (évidemment !),
- ii) huit composants-relations où il est possible d'en retrouver quatre d'importation et quatre d'utilisation et
- iii) dix composants-descriptions.
Le nombre d'OFL-composants peut sembler élevé au programmeur Java. Il est dû à la précision de notre système de paramètres qui offre une granularité relativement fine. Les différences sémantiques entre relations ou descriptions sont souvent masquées au programmeur par l'usage d'un même mot-clé dans un contexte différent. La présentation que nous donnons des OFL-composants de Java ne donne pas la valeur de chacun des paramètres mais plutôt une présentation de leurs principales caractéristiques. Nous signalons entre parenthèses les mots-clés associés à chaque OFL-composants.
Les composants-relations de Java. Les quatre premiers composants-relations sont des importations, les quatre suivants des utilisations.
- L'héritage interclasses (extends). Cette relation est utilisée pour affiner l'implémentation de la spécification d'un type de données. L'implémentation d'une spécification est réalisée dans une classe. L'héritage interclasses spécialise donc une classe. Il s'agit d'un héritage simple pour lequel les cycles sont interdits. Les primitives de la classe héritée sont importées dans la classe héritière. Il est possible de remplacer les attributs et de redéfinir les méthodes. Le polymorphisme s'applique de manière ascendante, c'est-à-dire que toute instance de l'héritière peut être vue comme instance de l'héritée.
- L'héritage interinterfaces (extends). Cette relation permet d'affiner la spécification d'un type de données. Elle est posée entre interfaces, l'héritière spécialisant les héritées. Au contraire de l'héritage interclasses, cette relation est en effet multiple. Le polymorphisme fonctionne de manière similaire à l'héritage interclasses.
- La concrétisation (extends). Cette relation permet de concrétiser l'implémentation de la spécification d'un type de données. Elle est posée entre une classe abstraite (héritée) et une classe non abstraite (héritière). Cette relation est identique à l'héritage interclasses si ce n'est qu'elle impose de donner, dans l'héritière, un corps aux méthodes abstraites de l'héritée et éventuellement à celles de ses super-classes lorsque celles-ci n'en possèdent toujours pas.
- L'implémentation (implements). Cette relation modélise l'implémentation de la spécification d'un type de données. Une classe peut ainsi implémenter une ou plusieurs interfaces. L'implémentation est donc une relation multiple. Si la classe est concrète, elle doit donner un corps à toutes les méthodes spécifiées dans les interfaces. Si elle est abstraite, elle peut donner un corps à certaines méthodes et conserver les autres abstraites. Le polymorphisme est identique à celui des relations d'héritage.
- L'agrégation. Cette relation modélise l'utilisation des services d'une description. Pour réaliser une telle utilisation, il suffit de déclarer et d'initialiser un attribut du type de la description utilisée (l'usage d'un paramètre de méthode, d'un résultat de fonction ou d'une variable locale du type de la description utilisée s'apparente à une agrégation). Contrairement aux quatre relations d'importation précédentes, les cycles sont autorisés pour l'agrégation. L'accès aux attributs de la description utilisée est direct, c'est-à-dire que la présence d'accesseurs n'est en rien obligatoire (sauf si la visibilité de l'attribut est restreinte, par exemple en le déclarant private). La durée de vie de l'objet utilisé est indépendante de celle de l'objet utilisateur et le même objet peut être utilisé par plusieurs objets utilisateurs.
- L'agrégation de classe (static). Cette relation modélise la notion bien connue dans les langages à objets d'attribut de classe. Elle est identique à l'agrégation si ce n'est le fait que l'objet utilisé est associé à la classe utilisatrice et non à ses instances.
- La composition. Cette relation modélise l'utilisation forte des services d'une description. Dans la littérature on emploie le terme composition entre deux classes au lieu d'agrégation pour dire qu'une instance d'une des deux classes est incluse dans l'instance qui l'utilise, et donc sa durée de vie est dépendante de celle de l'objet qui la contient/l'utilise. En Java cette notion de composition ne s'applique qu'aux descriptions qui utilisent un type primitif (par exemple : int).
- La composition de classe (static). La composition de classe est similaire à la composition mais défini un attribut de classe comme le fait l'agrégation de classe.
Les composants-descriptions de Java (les packages Java ne sont pas des descriptions au sens d'OFL, mais des ensembles de descriptions). De manière générale, nous nommons classes internes les classes membres statiques ainsi que les classes membres, les classes locales, les classes anonymes et les interfaces membres statiques. Nous avons recensé dix composants-descriptions (ici nous ne tenons pas compte des classes internes abstraites).
- La classe (class). La classe est une implémentation concrète d'un type de données. C'est une description non générique qui peut contenir des méthodes (ainsi que des constructeurs, initialiseurs et destructeurs) et des attributs. Elle est visible au sein de son paquetage mais cette visibilité peut être étendue ou restreinte par un qualifieur (public ou private par exemple). Elle a la capacité de créer des instances mais pas de les détruire explicitement. Enfin, la classe autorise la surcharge sans prendre en compte le type du retour des fonctions.
- La classe abstraite (abstract class). La classe abstraite est une implémentation abstraite d'un type de données. Cette description possède les mêmes propriétés qu'une classe mais elle peut décrire des méthodes abstraites (sans corps) et ne peut pas posséder d'instance propre.
- L'interface (interface). Il s'agit de la spécification d'un type de données. Au contraire d'une classe, une interface ne peut pas définir d'attribut (sauf les constantes de classe). De plus, ses méthodes sont toutes abstraites et elle ne peut donc pas créer d'instance.
- La classe membre statique (static class). C'est une implémentation, locale à une classe, d'un type de données. Sa particularité, par rapport à une classe, est d'être définie à l'intérieur d'une classe et non au plus haut niveau. Elle n'est d'ailleurs accessible qu'au travers de sa classe encapsulante.
- La classe membre (class). Il s'agit également d'une implémentation, locale à une classe, d'un type de données. Mais, à la différence de la classe membre statique, une instance de la classe membre est automatiquement associée à chaque instance de la classe encapsulante.
- La classe locale (class). Elle représente une implémentation, locale à une méthode, d'un type de données. Elle n'est visible qu'à l'intérieur de sa méthode encapsulante. En dehors de cela elle est équivalente aux autres composants-descriptions de classe.
- La classe anonyme (class). La classe anonyme est une implémentation, locale à une expression, d'un type de données. Elle est équivalente à une classe locale mais n'est visible qu'au sein de son expression encapsulante. De plus, n'ayant pas de nom, il n'est pas possible de la référencer et donc d'en hériter. Enfin, de par sa structure syntaxique, si elle implémente une interface, elle ne peut en implémenter qu'une.
- L'interface membre statique (static interface). Il s'agit d'une spécification, locale à une classe, d'un type de donnée. C'est l'équivalent de la classe membre statique sous la forme d'une interface.
- Le tableau. Il représente la structure de donnée de même nom, bien connue des informaticiens. C'est donc une collection indexée et de taille fixe d'entités d'un type défini. Le tableau est un cas particulier en Java. Chaque tableau est une instance d'une classe virtuelle (cette classe n'existe pas mais tout se passe comme si elle existait vraiment) représentant son type. Exemple : un tableau d'entiers est de type int[].
- Le type primitif. Le type primitif est la représentation d'un type de base du langage. Il permet de décrire les éléments essentiels des applications : booléens, caractères, octets, entiers courts, entiers, entiers longs, flottants et flottants doubles. Remarquons que chaque type primitif décrit une valeur et non un objet mais qu'une classe existe pour représenter chacun d'eux. Par exemple, la classe Integer permet de considérer un int comme un objet.
L'Evolution du modèle OFL
Depuis l'écriture de la thèse de Pierre Crescenzo un certain nombre d'évolution ont été définies notamment dans le cadre de la thèse de Dan Pescaru afin de pouvoir mieux prendre en compte la sémantique des aspects spécifiques à un langage. Nous avons en particulier introduit le concept de modifier dans OFL. Un premier survol de l'approche est décrit dans ce rapport.
Le MOP d'OFL
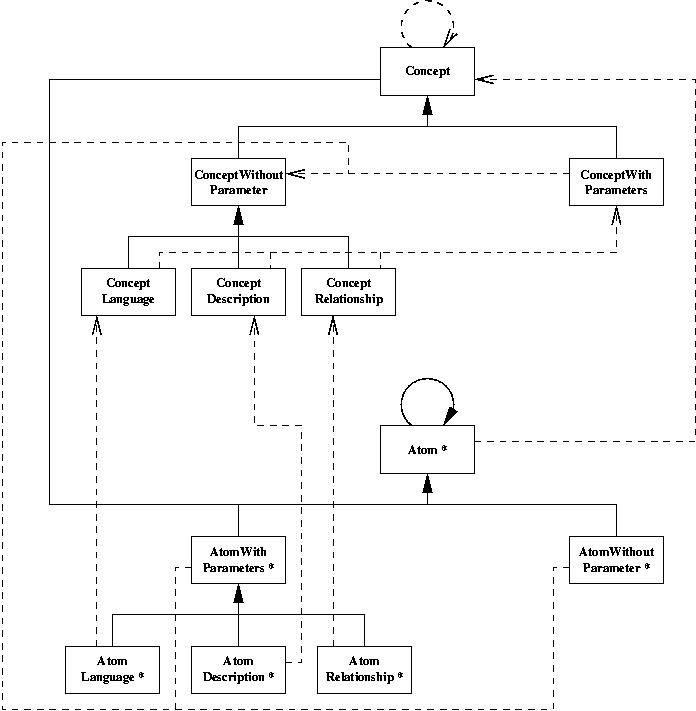
Le MOP d'OFL propose une réification à la fois des entités modélisant une application et de la sémantique opérationnelle du langage utilisé. Dans le but de pouvoir étendre cette réification au fur et à mesure des besoins, la réification du modèle OFL supporte en plus la description d'un protocole méta-objet permettant d'ajouter facilement une nouvelle entité qui est soit nouvelle, soit une autre réification d'une entité existante. La modélisation (indépendament de tout langage cible) du MOP d'OFL est décrite dans le schéma ci-dessous. De nombreuses adaptations ont du être réalisé pour développer l'implémentation en Java de ce dernier en particulier à cause de l'absence de niveau méta en Java..
Les actions OFL : Des objets de 1ère classe
L'ensemble des actions est répertorié dans la thèse de Pierre Crescenzo (voir ici); elles prennent en compte la valeur des paramètres associés aux OFL-composants.Un large spectre d’utilisation des métainformations est possible. Il s’étend jusqu’à la génération d’un compilateur ouvert qui, par la mise en œuvre de toutes les méta informations, permet la modélisation d’une grande variété de langages. Compte tenu de ces objectifs, il est important de pouvoir intégrer de nouvelles actions à la demande. L'approche sera décrite prochainement.




